








ChatGPTは便利ですが、以下のように感じたことはありませんか?
- オフラインで使えない
- 機密データを入力するのが不安
- 毎月の課金が気になる
そんな方におすすめなのが、ローカルで動く生成AI(ローカルLLM)です。
本記事では、初心者でも扱いやすい「LM Studio」を使い、
Qwen3.5をローカル環境で動かす方法を解説します。
実際めっちゃ簡単でした。
実際にRTX2070環境で動作確認もしているため、
「自分のPCで動くのか?」という不安も解消できる内容になっています。
LM Studioとは
LM Studioは、ローカル環境で大規模言語モデル(LLM)を実行できるツールです。
特徴としては、GUIベースで直感的に操作できる点にあります。
従来、ローカルLLMの実行にはコマンド操作が必要なケースが多く、初心者にはハードルが高いものでした。
しかしLM Studioでは、モデルの検索・ダウンロード・実行までをすべて画面操作で完結できるため、初めての方でも比較的簡単に環境を構築できます。
同じローカルLLM環境としてよく比較されるツールに「Ollama」がありますが、それぞれ特徴が異なります。
| ツール | 難易度 | 特徴 |
|---|---|---|
| LM Studio | 低 | GUIで簡単に操作可能 |
| Ollama | 中 | CLI中心で柔軟性が高い |
特に「とりあえずローカルでAIチャットを試してみたい」という方には、LM Studioが最も扱いやすい選択肢と言えるでしょう。
Qwen3.5とは
Qwen3.5は、Alibabaが開発している大規模言語モデル(LLM)です。
比較的新しいモデルでありながら、軽量モデルから高性能モデルまで幅広いラインナップが用意されているのが特徴です。
特にローカル環境での利用を考えると、この「軽量モデルの存在」は非常に重要です。
高性能なモデルは精度が高い一方で、動作に高スペックなGPUが必要になるため、一般的なPCでは扱いづらいケースもあります。
その点、Qwen3.5は以下のように複数のサイズが用意されており、環境に応じて選択できます。
- 7B:軽量で動作しやすい(個人PC向け)
- 14B:バランス型(性能と速度の両立)
- 32B以上:高性能だがハイスペックGPUが必要
日本語性能についても実用レベルに達しており、日常的なチャットや簡単な文章生成であれば十分に活用可能です。
LM StudioでQwen3.5を使う手順
ここからは実際の手順です。
① LM Studioをインストール
公式サイトからダウンロードしてインストールします。

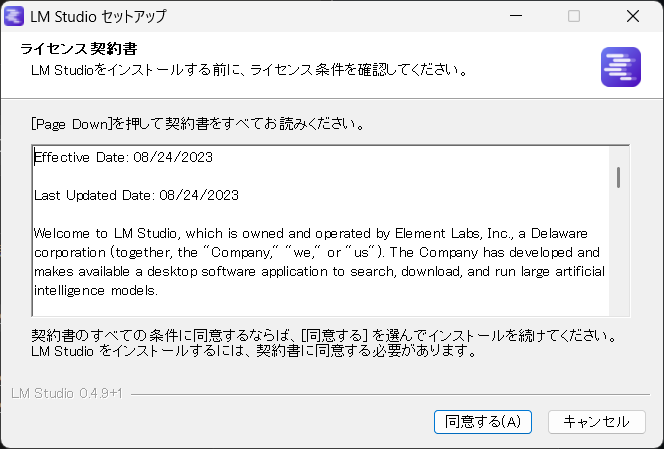
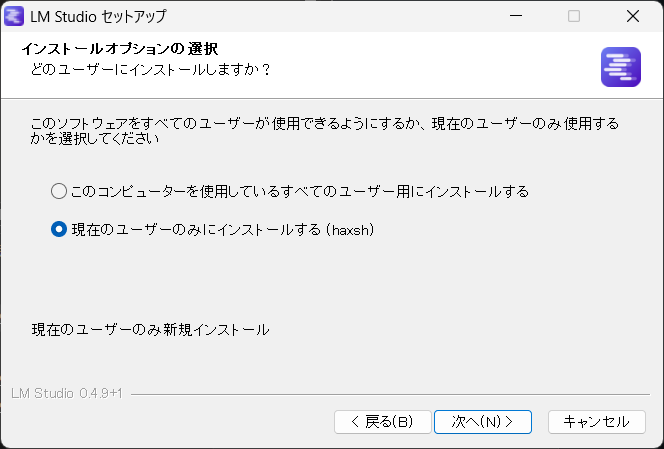
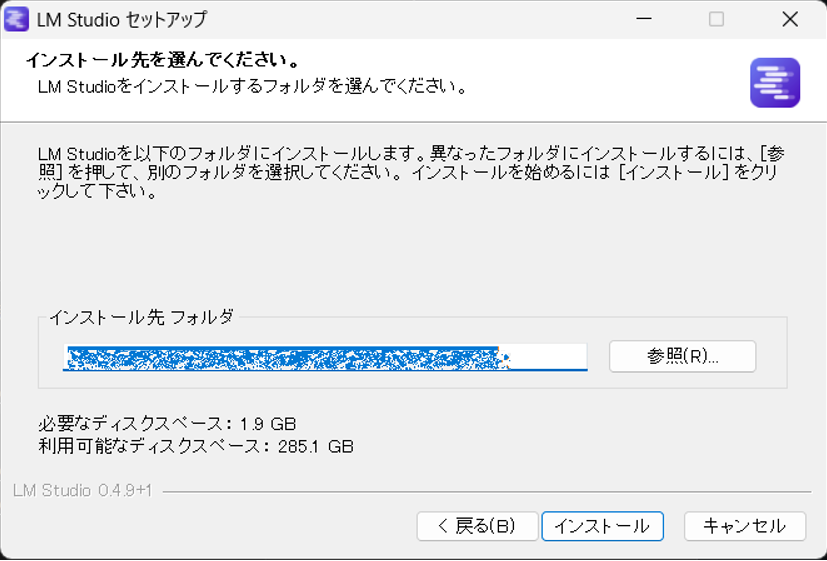
完了したら起動します。
Geminiをお勧めされますが一旦スキップしましょう
開発者モードと起動時にローカルAIサーバーを自動起動するかどうかですがこのままでOK
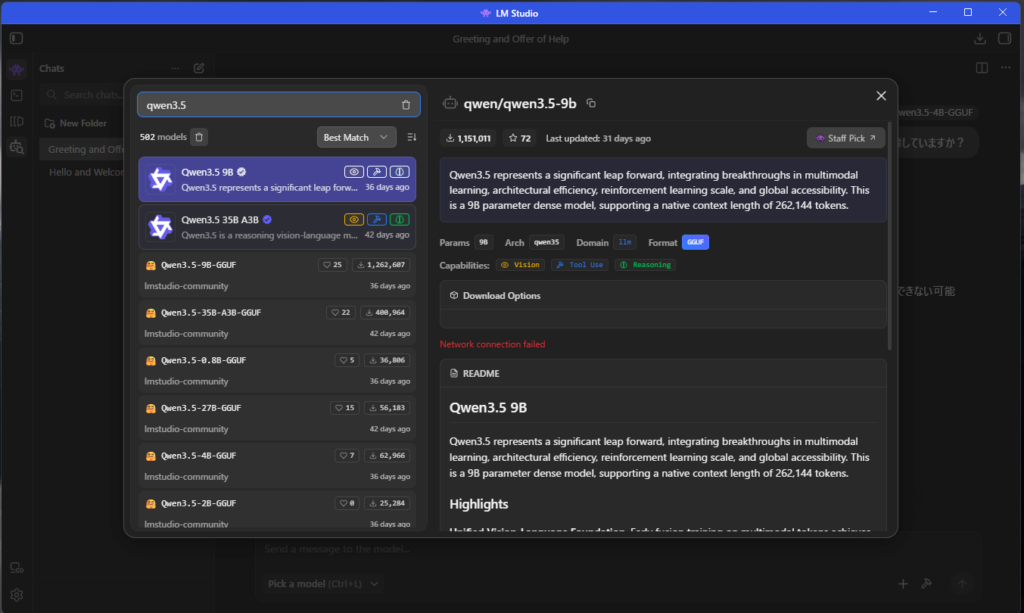
② モデルを検索
LM Studioを起動後、「Search」からモデルを検索します。左側のロボット虫眼鏡のマークです
Qwen3.5
で検索すればOKです。
いっぱい出てきます。
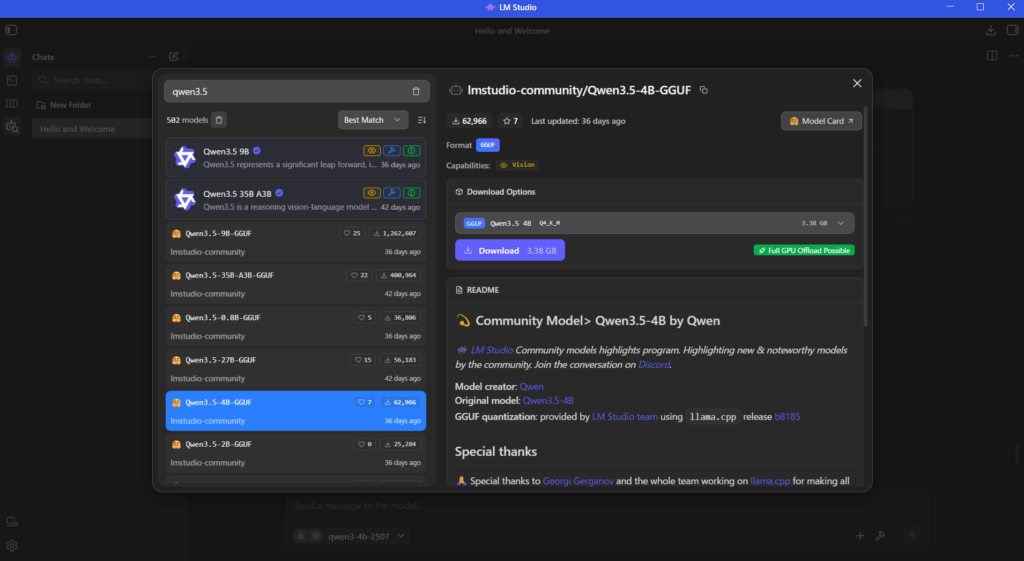
③ モデルをダウンロード
使用したいモデルを選択し、ダウンロードします。
今回はQwen3.5の「Qwen3.5-4B-GGUF」にしました、
AI曰く、RTX2070が快適に使えるのがこのモデルだそう。。。
⑤ チャット開始
Chatsにて真ん中にあるNewchatを選択
ここでテキストを入力できる画面が表示されるのでテキストを打ってみます
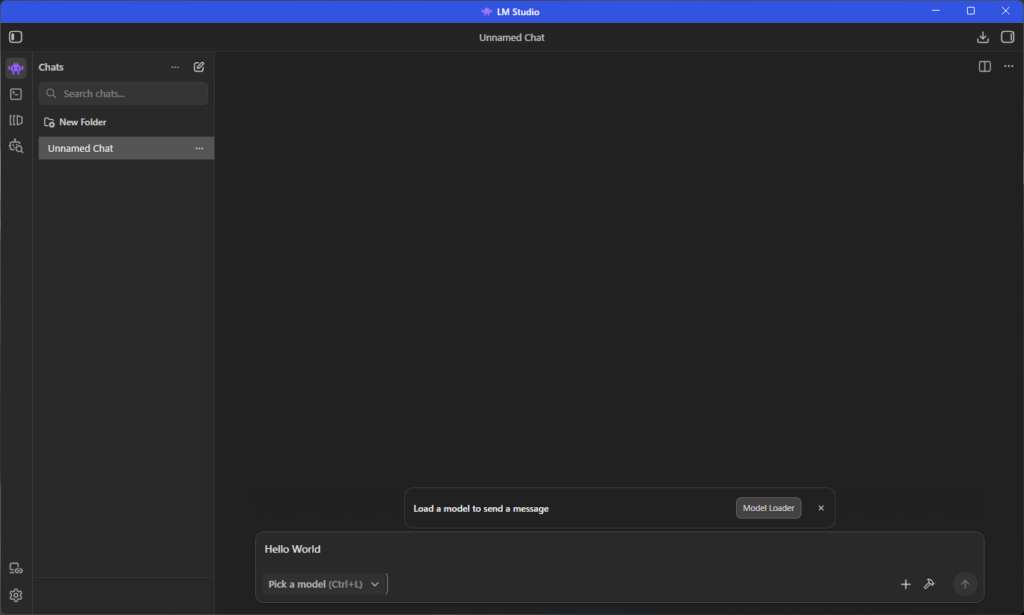
モデルを選択できていなかったので、Pick a modelをクリックし、モデルを選びます。
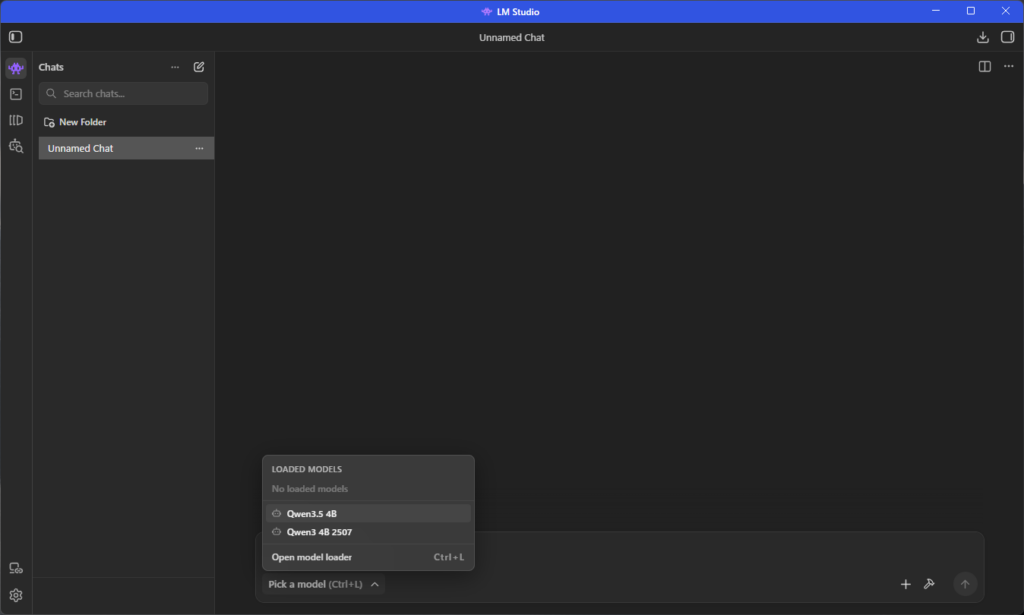
なんかよくわからんものが出てくるのでとりあえず、LoadModelします
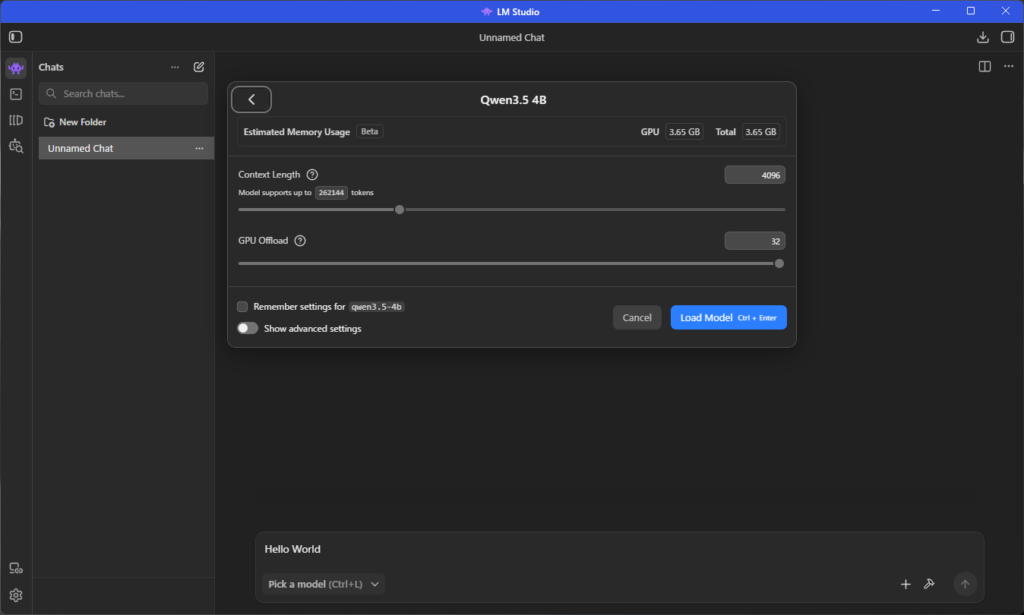
ロード(数秒)できたみたいなのでエンター!
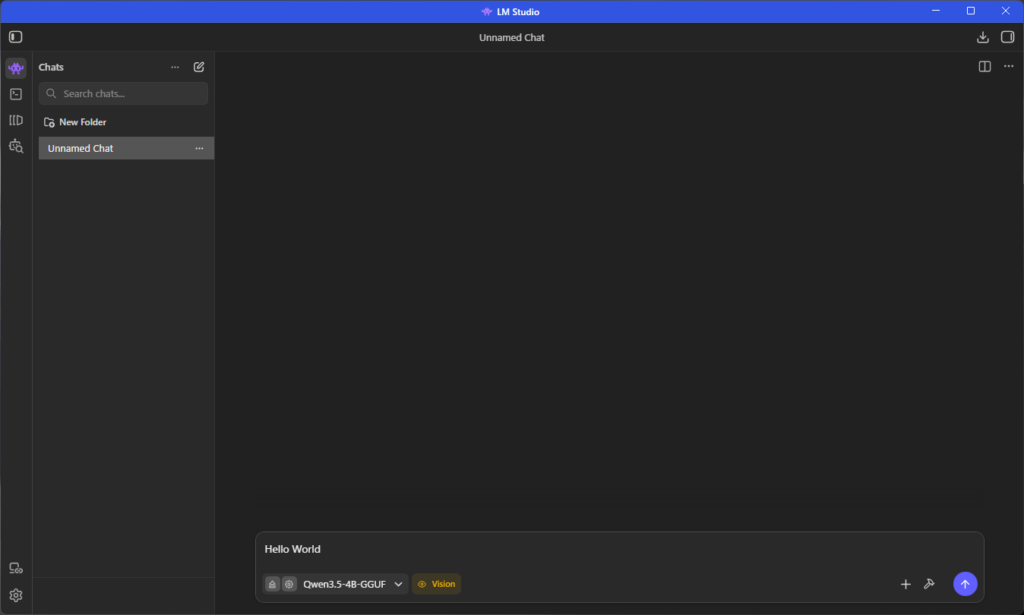
するとThinkingしてます。。。
そんなに考えなくてもいいよと言いたいw
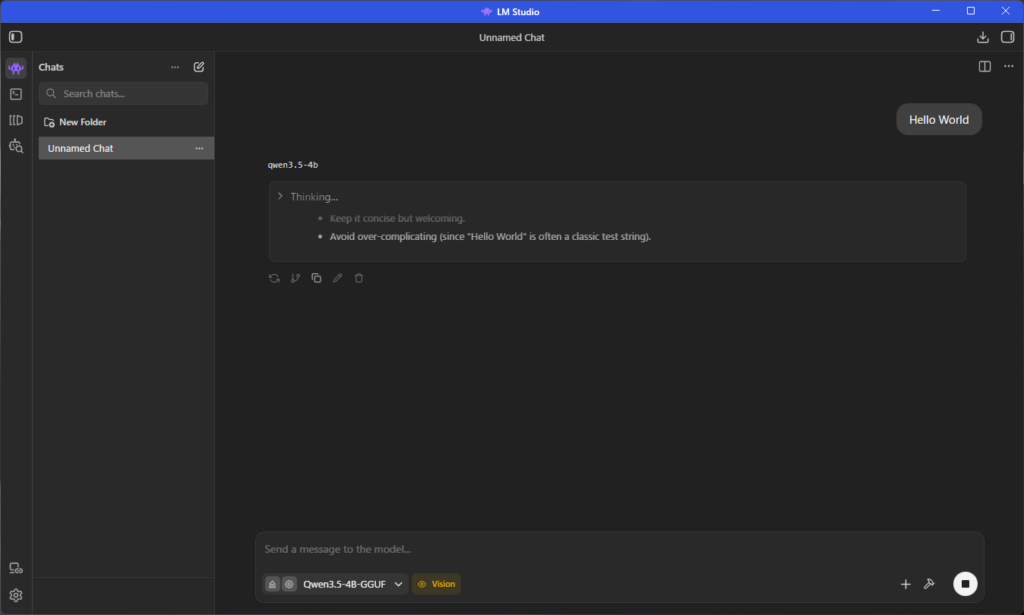
9秒考えて、Hello there! 👋 How can I help you today?と返ってきました!wえらい!w

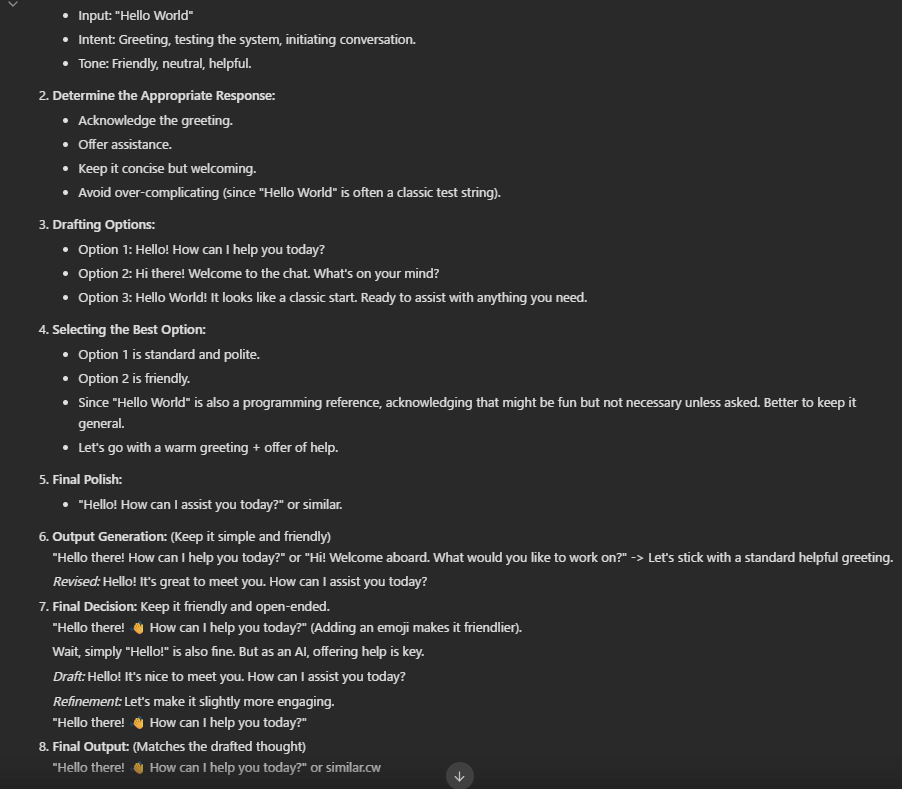
Thingkingの中身はこんな感じ、仕組みが可視化できるの良いですね
GPUどれだけ使うか
ローカルLLMでは、GPUが使われているかが非常に重要です。
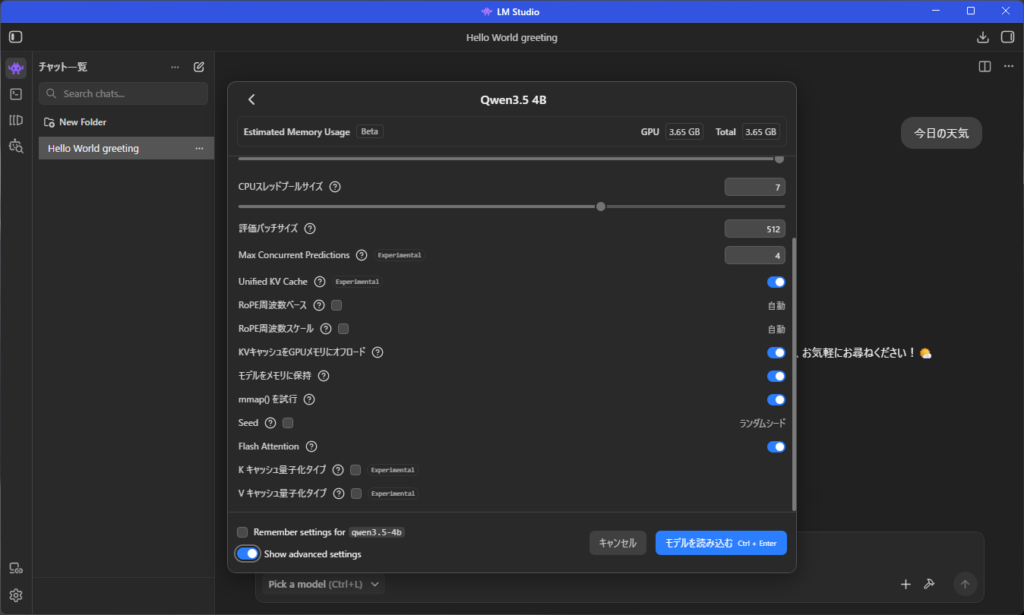
このロードモデルの時にGPU3.85となっているのでこんだけ必要ですよという意味だそうです、
このContext Length(コンテキスト長)というのを伸ばすと会話を覚える量が増える?みたいな感じだそうでまだよくわかってないです。。。
AI曰く、初期値がおすすめだそう、パソコンが壊れたら怖いので、このままでやりました
Show advenced settingsを見たらめっちゃ設定できるけど、よくわからん!
実際の確認方法
- タスクマネージャーでGPU使用率を見る
- 応答速度を見る
3Dが出てますね
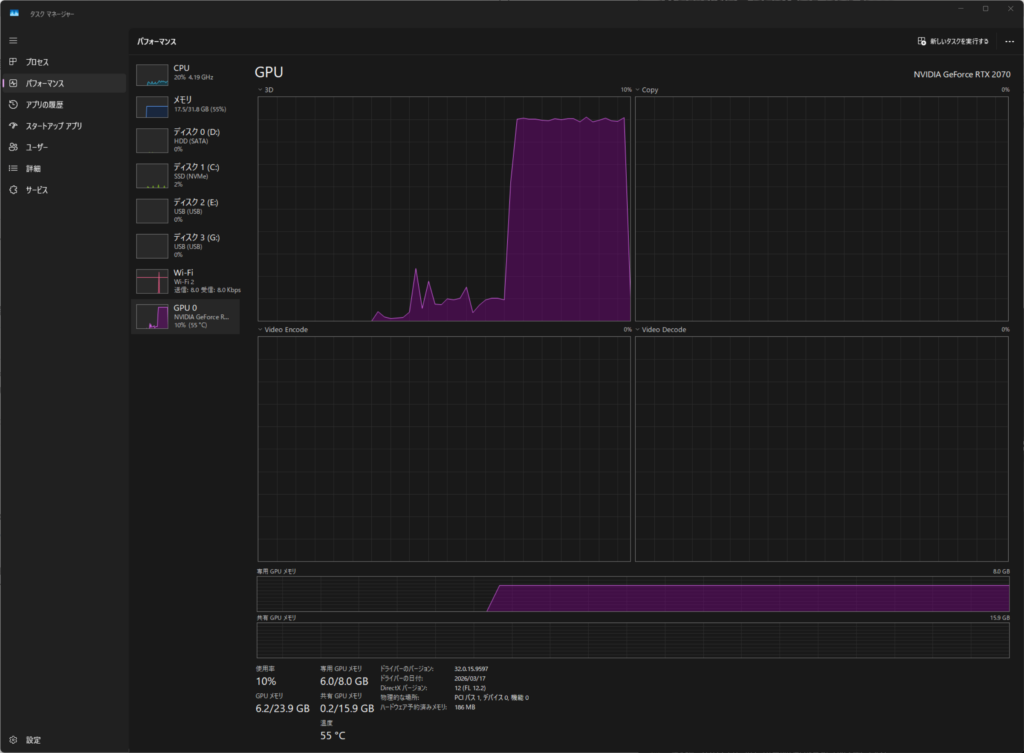
実測結果(筆者環境)
- GPU:RTX2070
- モデル:Qwen3.5 7B
- 応答速度:約15秒
CPUのみだとかなり遅くなるため、GPU利用はほぼ必須です。
今日の天気と入力すると16秒くらいかかって下のように返ってきました。オフラインだからこういう回答になったんだろうなという感じです。

ChatGPTとの違い
| 項目 | ChatGPT | ローカルLLM |
|---|---|---|
| 精度 | 高い | やや劣る |
| プライバシー | 低 | 高 |
| コスト | 月額 | 無料 |
| 自由度 | 制限あり | 高い |


コメント